
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- method dispatch
- value sementics
- IOS
- 2021wwdc
- sectionHeader
- swinject
- sendable
- compositional layout
- diffabledatasourcesnapshot
- reference sementics
- dynamic dispatch
- itemidentifiertype
- projectedvalue
- container
- 우유혁명
- Asynchronous
- propertywrapper
- arc in swift
- hashable
- di library
- SWIFT
- 21wwdc
- JSON
- DiffableDataSource
- uinib
- Di
- collectionView layout
- assembly
- vwt
- itemidentifier
- Today
- Total
Onemoon Studio
SOLID Principle 본문
코드를 작성하다보면 SOLID Principle이라는 규칙을 자주 보고는 한다. 물론 이를 공부한다고 모든 코드를 SOLID에 입각한 코드로 변경하는 것은 무리다. 하지만 객체지향을 공부하는 사람으로써 바이블격인 SOLID를 공부하고 이를 정리해야겠다는 생각이 들었다. 글의 순서는 아래와 같다.
저 또한 배우고 있는 과정이기 때문에 문제가 있거나 잘못된 부분이 있다면 감사하겠습니다!
- SOLID Principle
- Single Responsibility Principle
- Open/Close Principle
- Liskov Substitution Principle
- Interface Segregation Principle
- Dependency Inversion Principle
SOLID Principle
- 어떤 장점이 있는가?
- 재사용성이 높은 코드를 만들어 컴포넌트화를 통한 생산성을 높힐 수 있다.
- 테스트가 가능한 코드를 만들어 관리할 수 있다.
- 여러곳에 묶여 있는 스파게티 코드를 만들지 않는 기준을 세울 수 있다.
- 변경에 유연하며 확장성이 높은 코드를 만들 수 있다.
- 결국 관리하는데 필요한 리소스가 줄어든다.
S (Single Responsibility Principle , 단일 책임 원칙 - SRP )
- 하나의 모듈은 하나의 이해관계자를 만족시켜야 한다.
- 여기서 모듈이란 데이터와 함수의 응집된 집합을 말한다. ( 보통 클래스 )
- 이런 관점에서 쉽게 말하자면, 단일 클래스는 단일 책임을 가지고 있어야 한다.
- 코드의 응집성을 높힌다.
Why?
처음에 모듈을 만들 때 이 규칙만큼은 쉽게 지킬 수 있을 것이다. 문제는 작은 기능이 하나둘씩 추가 되면서 시작된다. 처음에는 하나의 기능만 추가 된다고 하지만 하나만 추가 되리라는 보장은 없다. 계속해서 기능이 추가되고 점점 해당 모듈의 책임은 많아지게 된다.
해당 모듈의 책임이 많아 질수록 코드가 병합될 확률이 높아진다. 예를 들어 Alpha 클래스에 A, B 라는 책임을 갖고 있을때는 A와 B의 코드가 서로 병합되는 상황이 발생할 수도 있으며, 책임(기능)이 하나 둘씩 늘어날수록 그 가능성은 점점 커질 것이다.
이때 만약 A의 기능을 리팩토링 한다고 하자. 병합이 많아질수록 A 뿐만 아니라 다른 기능 또한 수정해야 할 가능성이 높아지며, 해당 기능이 제대로 동작하는지 또한 다시 확인해야 한다. 결국 이를 해결하기 위해서는 꼬인 끈을 모두 풀어내는 수 밖에 없으며, 기능이 많아질수록 이에 대한 비용은 기하 급수적으로 늘어나게 된다.
특히 iOS 의 경우 UIViewController가 대표적인 예라고 할 수 있다. UI, Network, Navigation 등등 모든 역할을 책임지기 때문이다. 이를 잘 나누는 것이 중요하다고 할 수 있다.
How?
첫번째로, 작은 피쳐를 그만 추가해라. 모듈, 컴포넌트, API 형식으로 분리하는것을 생각해봐라. 기능을 붙일 생각을 하지말고 라이브러리로 만들 생각을 해야한다.
그리고 하나의 기능을 할 수 있는 클래스를 만들어라. 만약 커다란 문제에 가로막혔다면 이를 분리해라. 그리고 분리한 클래스를 사용하는 클래스를 하나 만들어라
O ( Open / Close Principle , 개방/폐쇄 원칙 - OCP )
- 확장에는 열려있고, 변경에는 닫혀있어야 한다.
- 즉 개체의 행위는 확장할 수 있어야 하지만, 개체가 변경되어서는 안된다.
Why?
예를 들어서 Bread House 라는 클래스를 만들고 여기서 빵을 만들어서 판매한다고 하자. 초기에는 단팥빵만 판매한다고 생각했다. 따라서 단팥빵에 맞는 로고를 만들고, 기구를 들였으며, 저장 창고도 만들어놓았다. 그런데 어느날 Bread House 에서 카스테라를(확장) 팔아야 하는 상황이 왔다. 이미 단팥빵에 맞춰서 House를 설계했기 때문에 로고는 물론, 기구, 저장창고도 바꿔야 하는 최악의 상황이 나타날 수도 있다. 결국 이에 대한 비용은(변경) 굉장히 많을 것이다.
만약 처음부터 특정 빵에 전문화하지 않고, 다른 빵을 판매할 가능성이 있다고 고려한 다음 설계했다면 어땠을까? 확장에 대한 비용은 급격하게 줄어들 것이라고 확신한다. 이 방식이 OCP를 고려한 방식이다.
실제로 사용하는 예시를 들자면 network 에서 데이터를 가져온 뒤 이를 decode 하는 방식을 들 수 있다. 아래의 코드를 살펴보자 타입이 추가될때 마다 decode관련 함수를 추가해야할 것이다. 이때 타입이 수십개 추가된다면 어떻게 될까?
class Parent: Decodable { }
class Child: Decodable { }
func decodeParentData(_ data: Data) -> Parent {
let decoder = JSONDecoder()
return try! decoder.decode(Parent.self, from: data)
}
func decodeChildData(_ data: Data) -> Child {
let decoder = JSONDecoder()
return try! decoder.decode(Child.self, from: data)
}How?
아우를 수 있는 확장성이 높은 코드를 사용하는 것이 좋다. 제네릭, 상속, 프로토콜을 사용하도록 하자. 결국 다른 타입이 추가 되더라도, 기존의 코드는 최대한 건드리지 않으면서 새로운 타입에 대해서도 기존에 사용했던 기능들은 그대로 사용할 수 있어야 한다.
위의 예시를 Generic과 Protocol을 사용해서 변경한다면 Parent 혹은 Child 심지어 다른 타입이 추가되더라도 Decodable 프로토콜을 채택한다면 전혀 문제가 없을 것이다. 즉, 다른 타입이 추가되는 확장에도 문제가 없으며, decode 함수가 변경될 일이 없으므로 변경에도 닫혀 있는 코드이다.
func decodeData<T: Decodable>(_ data: Data, _ type: T.Type) -> T? {
let decoder = JSONDecoder()
return try? decoder.decode(type.self, from: data)
}
L ( Likov Substitution Principle, 리스코브 치환 원칙 - LSP )
- S가 자료형 T의 하위타입이라면 프로그램의 속성의 변경없이 자료형 T의 객체를 자료형 S의 객체로 교체할 수 있어야 한다.
- 상위 타입의 객체를 사용하는 곳에 하위 타입의 객체를 사용하더라도 의도한대로 동작이 되어야 한다.
- 객체는 프로그램의 정확성을 해치지 않으며, 하위 타입의 인스턴스로 바꿀 수 있어야 한다.
- 쉽게 말하자면 자식 클래스는 최소한 자신의 부모클래스의 행위는 수행할 수 있어야 한다는 말이다.
전형적인 위반 사례
해당 규칙이 제일 이해하기가 애매해서 대표적인 위반 사례를 가져왔다. Circle-elipse(sqaure-rectangle) Problem이다.
너비와 높이의 조회 및 할당 메서드를 가진 직사각형 클래스로부터 정사각형 클래스를 파생하는 경우를 예로 들 수 있다. 직사각형을 상위타입으로 생각하고, 정사각형을 하위타입이라고 하자.
하지만 직사각형과 다르게 정사각형은 넓이와 높이가 항상 같은 특징을 가지고 있다. 따라서 너비와 높이를 따로 관리하는 직사각형을 사용하는 프로그램에서 이와 다른 정사각형을 대체하는 경우 얘기치 못한 문제가 생길 가능성이 높다.
Why?
명확하게 경계를 긋지 않는다면 생길 수 있는 문제점들이 많기 때문에 해당 부분을 신경써야 한다. 위의 예시를 생각해보자. 직사각형을 부모로 생각하고 정사각형을 하위 요소로 생각했기 때문에 문제가 발생했다. 이는 잘못된 상속의 사례를 보여줌으로써 이를 활용할 수 있는 방안이 제한되는 것을 보여준다.
(클린 아키텍쳐에서는 이렇게 설명한다.) 이는 method의 override 가 어떻게 이루어져야 하는지를 설명하기도 한다. 예를 들어서 a라는 메서드를 오버라이드 했을 때 성공한 경우, 실패한 경우, 중간에 변경되어야 하는 경우 등의 흐름이 a라는 메서드와 동일해야 한다는 말이다.
a에서는 실패한 경우 message를 보내주는데, 오버라이드 한 메서드는 실패한경우 아무것도 일어나지 않는다면 이는 LSP를 어긴 것이다. 따라서 동일하게 동작한다는 것은 실제로 동일한 코드가 아니라 동일한 흐름을 가져야 한다는 것이다.
How?
다른 하위타입으로 대체가 되더라도 동일한 동작을 해야한다. 이를 위해서 상속의 범위를 잘 생각해야 한다. 사용하는 메서드가 전체를 아우르는 메서드가 맞다면 동일한 동작을 해야하며, 그렇지 않다면 따로 작성해야 함을 의미한다. ( Circle-elipse )
또한 method를 override 할 때 내부의 동작 흐름이 기존의 동작 흐름과 동일한지 생각해봐야 한다. 예를 들어서 a라는 메서드를 오버라이드 했을 때, 성공한 경우, 실패한 경우, 중간에 변경되어야 하는 경우 등의 흐름이 a라는 메서드와 동일해야 한다는 말이다. a에서는 실패한 경우 message를 보내주는데, 오버라이드 한 메서드는 실패한경우 아무것도 일어나지 않는다면 이는 LSP를 어긴 것이다. 따라서 동일하게 동작한다는 것은 실제로 동일한 코드가 아니라 동일한 흐름을 가져야 한다는 것이다.
따라서 오버라이드를 했는데 다른 부분을 수정하거나 추가한다면 이는 잘못된 것이다. ( 치환해도 동일하게 작동해야 한다는 뜻이 이 뜻이다. ) 서브클래스를 제외하고서는 다른 부분이 변경되어서는 안된다.
I ( Interface Segregation Principle, 인터페이스 분리 원칙 - ISP )
- 일반적인 인터페이스보다 각각의 구체적인 인터페이스를 가지는 것이 낫다.
- 불필요한 기능이 들어간 인터페이스 설계를 피해야 한다.
Why?
애초에 불필요한 기능은 넣을 필요가 없다. 하나의 일만 하는데 다섯개의 기능이 들어가 있다면, 나머지 4개의 코드를 관리하는데 드는 비용은 전혀 중요하지 않은 비용이 된다.
How?
Fat Interface 를 만들지 말자. 필요한 기능만 인터페이스에 추가해서 사용하도록 하며, 여러개를 사용하는 경우는 이를 합치면 된다. Swift에서의 대표적인 예로 Codable 이 있다. Codable의 경우 Decodable 과 Encodable protocol이 합쳐진 typealias 이다. 따라서 두개의 기능이 필요 없다면 Decodable, Encodable 한쪽만 사용하면 된다. Decode만 수행하면 되는데 굳이 Codable을 쓸 필요가 없다. 바나나를 원하는데 고릴라와 함께 온다면, 바나나는 얻었지만 고릴라는 귀찮은 존재가 된다. 그만큼 세분화 해서 나눠야 적절한 곳에 배치할 수 있다.
D ( Dependency Inversion Principle, 의존관계 역전 원칙 - DIP )
- loose coupling module을 만들기 위한 principle이다.
- 상위 레벨 클래스가 하위 레벨 클래스에 의존하지 않도록 한다.
- 다시 말해서 상위 레벨 클래스는 하위 레벨 클래스의 구현과 독립되어야 한다.
- 여기서 상위 레벨이란 ViewController / ViewModel 등을 말하며, 하위 레벨이란 Storage / Network Module 을 말한다.
Why?
decoupling 을 위해서 사용이 되는 principle이다. decoupling 이란 strong coupling이 아닌 loose coupling을 추구하는 과정을 말한다. 다른 구체화된 개체에 강하게 의존했을 때 strong coupling 이 생기게 된다. 이때 하나의 변수를 수정할 때에도 여러 의존성이 서로 묶여있기 때문에 쉽게 변경이 불가능 할 것이다. 이런 상황을 strong coupling 이라고 하며, 이가 많아질 수록 코드의 확장성은 떨어지고, 유지보수 비용은 급격하게 증가하게 된다.
또한 구체화된 개체보다 추상화된 개체를 선택하는 것이 변동성이 작기 때문이다. 프로토콜(추상화)를 의존한다면 내부의 동작(구체화된 개체)에 대해서는 신경쓰지 않아도 된다. 즉 구현체의 변경에 민감하지 않다. 반대로 구현체를 의존하게 된다면 구현체가 변경 될 때마다 민감하게 반응을 해야 할 것이다.
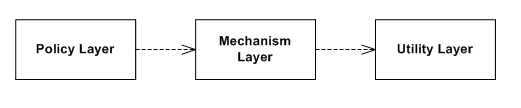
How?
high-level 에서 단순히 low-level을 참조하는 것이 아닌 추상화를 서로 참조하는 방식을 사용한다. 쉽게 말해 기존에 A → B의 형태로 코드가 작성되었을 때는 A 와 B가 tight coupling 이지만, A → B protocol ← B 형태의 코드를 작성하게 된다면 loose coupling 이 되며 서로의 변경에 영향이 적어지게 된다.
이를 설명할 때 dependency inversion은 low-level에서 high-level을 참조하는 것이 아니다. 단지 기존의 흐름을 바꾸는 것을 inversion으로 표현하는 것으로 알고 있다. 특히 예시의 화살표 방향을 살펴보면 B는 참조를 받는 입장에서 B protocol을 참조하는 방향으로 바뀌는것을 확인할 수 있다. 기존의 제어 흐름과 소스코드의 의존성이 반대가 되는 것이다.
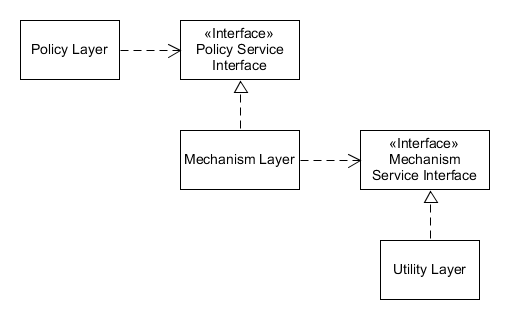
reference
클린아키텍쳐 ( book )
'iOS & Swift' 카테고리의 다른 글
| Swinject 사용하기 ( 2 / 2 ) (0) | 2021.04.21 |
|---|---|
| Swinject 사용하기 ( 1 / 2 ) (1) | 2021.04.21 |
| Responder Chain ( 앱은 유저의 인터렉션을 어떻게 처리하는가 ? ) (0) | 2021.03.18 |
| Reducing Dynamic Dispatch ( 성능향상 ) (0) | 2021.01.24 |
| Encoding 정복하기 (0) | 2020.11.23 |


